Quote of the week
“The future is already here - it’s just not evenly distributed.”
- William Gibson

Edition 39 - September 28, 2025
“The future is already here - it’s just not evenly distributed.”
- William Gibson
NASA has locked in a date for its first crewed mission to orbit the Moon in more than fifty years, setting April 2026 as the latest possible launch for Artemis 2. The flight could come as early as February and will carry three American astronauts and one Canadian around the lunar surface.

The mission, long delayed by setbacks, will not land on the Moon but instead pave the way for Artemis 3, which aims to put humans back on the surface. The push comes as the United States faces mounting pressure from China’s space program, which is targeting its own crewed Moon mission by 2030. Officials have described this as a “second space race,” echoing the Cold War rivalry between the U.S. and the Soviet Union.

This feels exciting not only because it marks humanity’s long-awaited return to lunar exploration, but also because competition in space does not need to be hostile. A race with China can push both nations to achieve more, faster. Ideally it becomes less about winning for its own sake and more about advancing science, technology, and our shared future beyond Earth.
Apple has started laying the groundwork to support Anthropic’s Model Context Protocol (MCP) inside its platforms. Code spotted in the latest developer betas of iOS 26.1, iPadOS 26.1, and macOS Tahoe 26.1 points to MCP integration with App Intents — the framework that already lets apps surface actions and content to Siri, Spotlight, Shortcuts, and more. In practice, this could allow AI agents like ChatGPT or Claude to interact directly with Apple apps and services without requiring developers to build custom integrations from scratch.

First introduced by Anthropic in late 2024, MCP has quickly become the industry standard for connecting AI systems to data sources and APIs. Instead of siloed integrations, MCP offers a universal interface — much like HTTP did for the web. Companies from Notion and Zapier to Google, Figma, and Salesforce have already adopted it. With Apple now signaling interest, the ecosystem of AI agents may soon extend natively to the Apple ecosystem.

MCP, or Model Context Protocol, is essentially a universal translator between AI and apps. But do we really need it? The short answer is yes. Without MCP, every app would require its own special wiring for AI, creating friction and making assistants less useful. With MCP, that wiring is standardized — meaning your AI doesn’t need to “learn a new language” each time it plugs into a new service. For the average person, it’s like having one universal charger that works with every device instead of a messy drawer full of cables.

For Apple, this could unlock entirely new experiences. Imagine Siri handing off a complex task to Claude or ChatGPT, which then books travel through Safari, schedules events in Calendar, and drafts documents in Pages — all autonomously. Developers could expose their app’s features to AI agents without heavy lifting, making Apple devices more powerful out of the box. For users, the promise is a more capable digital assistant that doesn’t just answer questions, but gets real work done across your iPhone, iPad, and Mac.
Low risk defi is the conservative side of onchain finance. Instead of chasing jackpot yields, it focuses on safe and transparent tools like payments, simple savings, fully collateralized lending, and basic synthetic assets. The goal is to give people and businesses reliable access to familiar financial products — stable currencies, competitive interest, and tokenized stocks or bonds — without depending on fragile local banks. Vitalik Buterin makes the case here: Low risk defi.
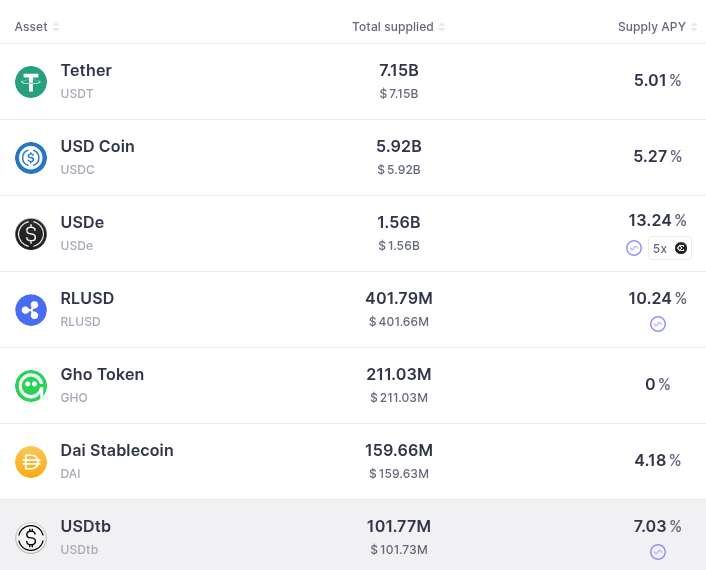
Ethereum has long struggled to balance apps that pay the bills with those that match its mission. Revenue has mostly come from NFTs, memecoins, and complex yield loops, while experiments in identity and privacy saw little traction. The argument now is that low risk defi can be Ethereum’s steady engine, like ads are for Google — dependable income that supports riskier experiments. With protocols maturing and transparency reducing hidden risks, the timing looks right.
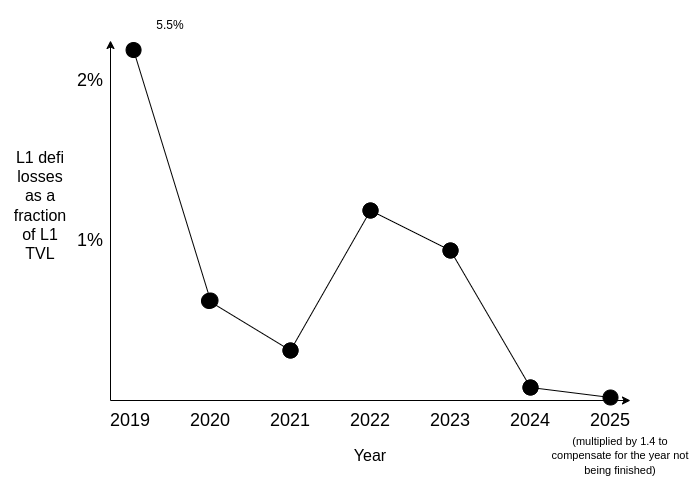
The impact could be broad. In developed countries, low risk defi means instant settlement, programmable accounts, and better competition for deposits and payments. In developing countries, it offers stable savings, cheap remittances, and reliable credit without fragile intermediaries. For the global economy, it opens financial rails, broadens investor access, and improves transparency in risk pricing. If it stays conservative and well collateralized, low risk defi could be the foundation that makes the rest of the ecosystem sustainable.

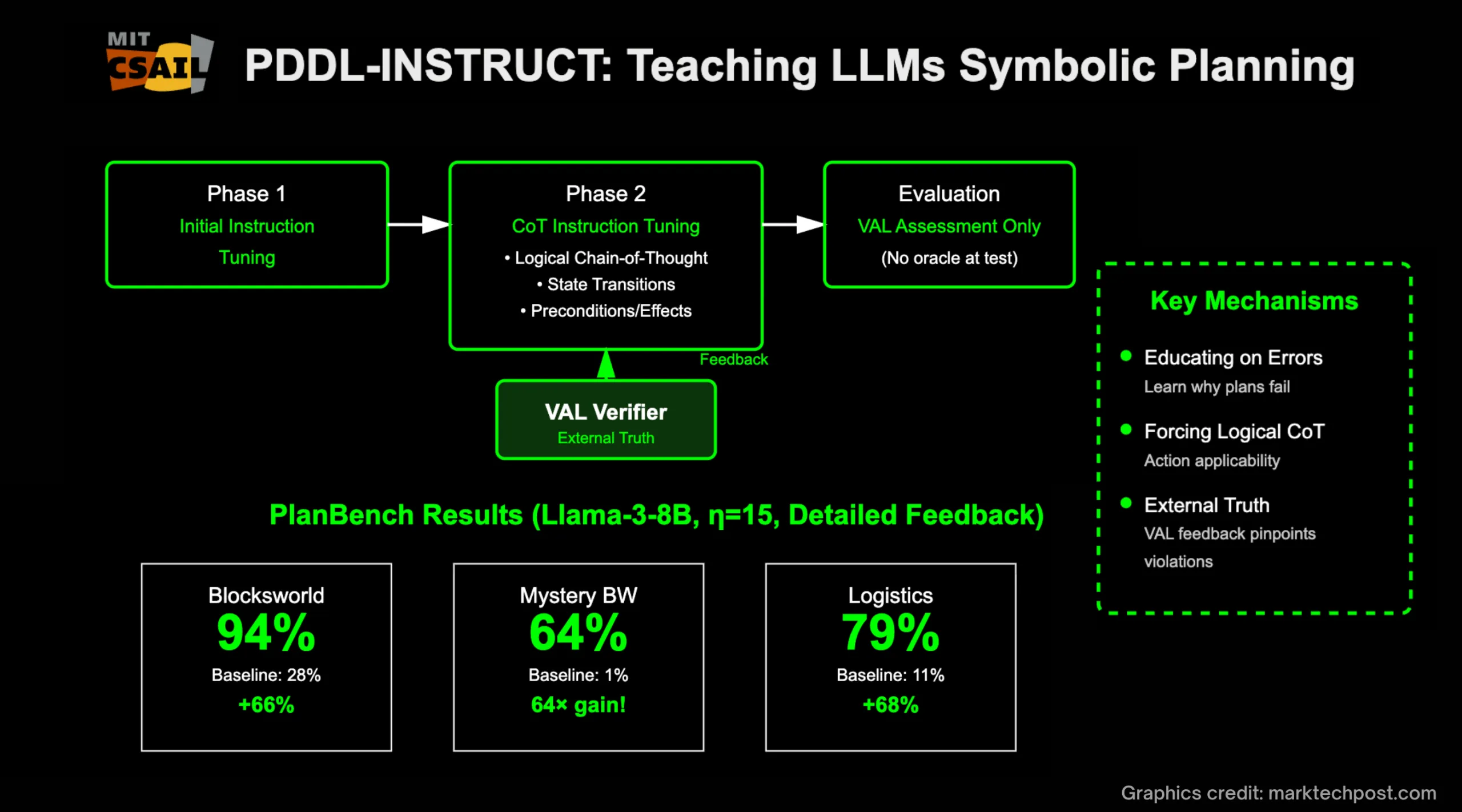
A new paper from MIT CSAIL and collaborators proposes PDDL-INSTRUCT, an instruction tuning recipe that teaches large language models to do formal symbolic planning. Instead of treating plans as loose step lists, the method forces the model to reason about preconditions, effects, and invariants at every step, then check its own work with a verifier before moving on. In practice, it runs a two phase process: first tune on plan examples, then tune again with logical chain of thought traces so the model learns to prove action applicability and state transitions. The result is a planner that can generate a plan and justify each transition in the style of PDDL, the standard language for classical planning. Read the paper here.

The team evaluates on PlanBench across three domains that stress different reasoning muscles: Blocksworld, Mystery Blocksworld with obfuscated predicate names, and Logistics with trucks and planes. Using Llama 3 8B and GPT 4 as bases, their best variant reaches plan validity of 94 percent in Blocksworld, 79 percent in Logistics, and 64 percent in Mystery Blocksworld, with detailed verifier feedback beating simple valid or invalid feedback. They report sizable absolute gains over baselines and over standard instruction tuning, and they verify plans with VAL so a plan only counts if every action is applicable and the goal is met. Training was modest by modern standards, using two RTX 3080 GPUs and roughly thirty hours end to end.
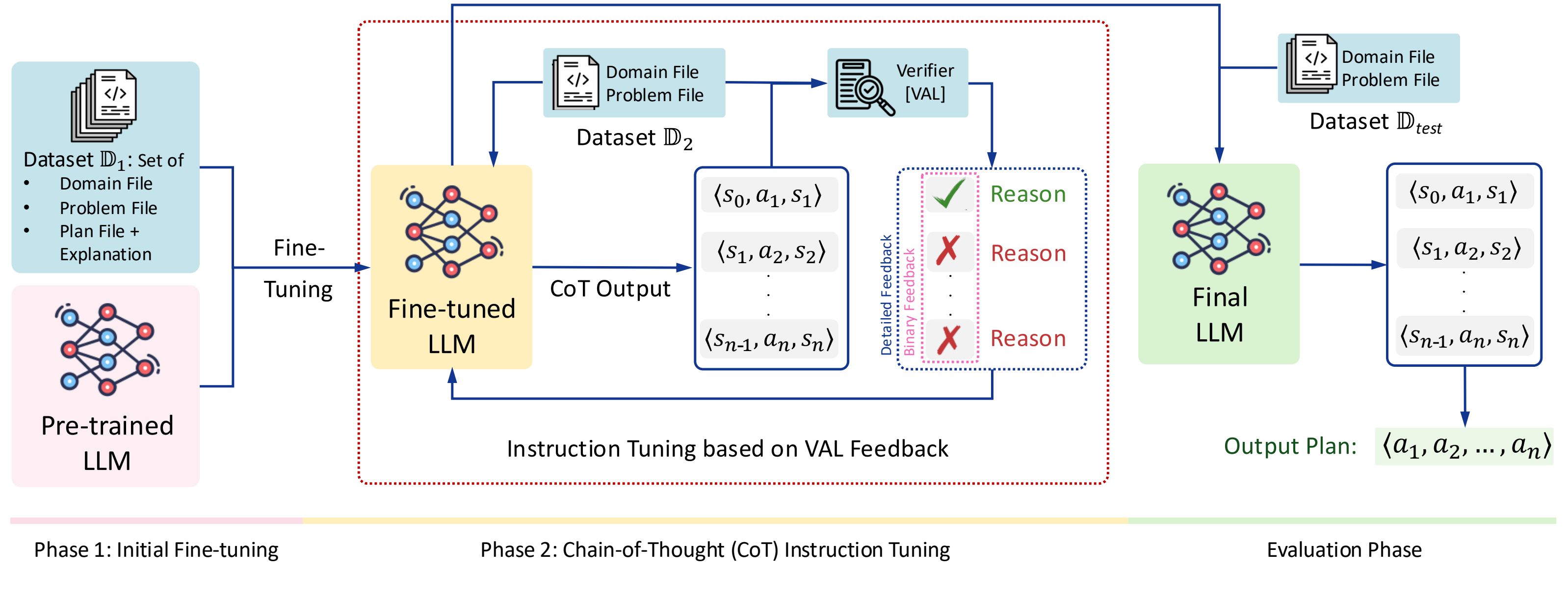
Why this matters: instruction tuning here is not about more tasks, it is about teaching models how to reason. PDDL gives you a small set of symbols that describe states, actions, and goals, which makes plans auditable. Normal LLMs are great at language but brittle at long horizon decisions. Reasoning tuned models add explicit intermediate checks so they can inspect whether an action is allowed, apply effects, and preserve constraints before they continue. If you combine that with external tool calls and simulators, you get a pathway to assistants that can plan, verify, and then act, all while exposing a readable proof of why each step should work.
A concrete example is parcel routing. Imagine a regional shipper that must move packages from multiple origins to destinations under changing capacity and weather. A planning aware LLM receives a PDDL domain for trucks, planes, airports, depots, and constraints like load limits and location connectivity. It proposes a sequence such as load, drive, unload, fly, reload, and deliver, checking at each step that the vehicle is at the right place, capacity allows the action, and the package ends in the goal state. If a runway closes, the model can replan by swapping actions that remain valid under the rules. The same pattern could extend to hospital scheduling, factory changeovers, or home robotics, anywhere you want a plan that is both executable and explainable.
Researchers from Forschungszentrum Jülich and RWTH Aachen have introduced a new analog in-memory computing (IMC) architecture that radically speeds up the self-attention mechanism in large language models. Instead of shuttling vast key and value caches back and forth between GPU memory and SRAM, their design performs the dot-product operations directly inside volatile gain cell memory arrays. These arrays handle multiplications in the analog domain and communicate between stages without expensive analog-to-digital conversions. The approach implements Sliding Window Attention, which tracks only the most recent tokens rather than the entire sequence, drastically reducing memory pressure.

To adapt existing transformer weights to the quirks of analog hardware, the team devised an initialization algorithm that scales layers to match hardware behavior. Even with these constraints, the system achieved performance comparable to GPT-2 while cutting energy consumption by up to five orders of magnitude and reducing latency by up to two orders compared to GPUs. By eliminating the need to constantly reload large caches, this chip-level design offers a path toward ultra-fast, low-power inference engines for large models. Read the paper here.
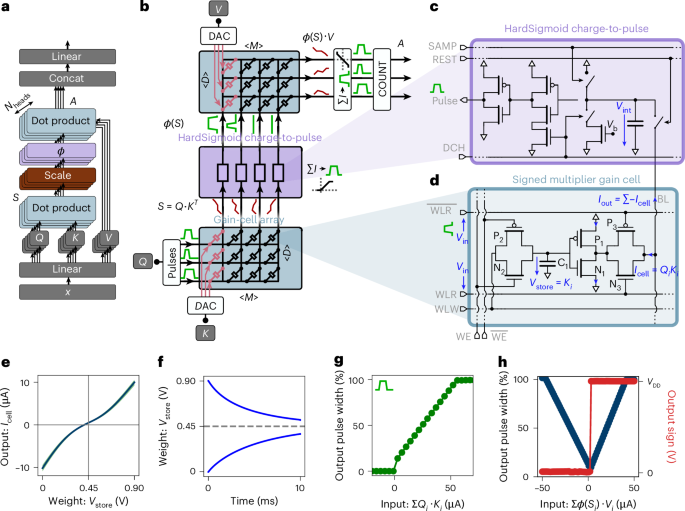
The numbers are striking: the researchers estimate speedups approaching 100x relative to an Nvidia H100 GPU and energy reductions on the order of 70,000x. If such gains hold at scale, it would mean that the bottleneck of memory access in transformers could be nearly erased. Beyond raw efficiency, the design reduces the footprint of cache storage, meaning smaller and less power-hungry hardware could run models that today demand massive GPU clusters. This is not about building a faster GPU, but about rethinking where and how the most expensive operation in transformers — the attention step—takes place.
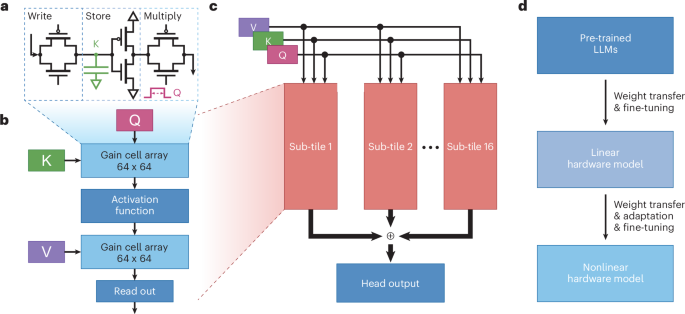
The implications are profound. If models can be run with 100x less compute and 70,000x less energy, inference could shift away from centralized data centers and closer to the edge: phones, robots, cars, even appliances. Imagine a smartphone running a local LLM that handles conversations, planning, or vision tasks without constant cloud calls. Or a warehouse robot that performs natural language task planning on-board rather than streaming queries to a server farm. The analog IMC attention mechanism could enable this by collapsing the biggest computational and energy burden in transformers into a compact, efficient memory block. If it scales, this is not just a hardware speedup but a shift in where AI can live.
Over a year ago, Paul Kinlan began tinkering with a browser that does not just display the web but can rewrite it for you. His first experiment, Fauxmium, used Puppeteer to intercept requests and respond with content from a large language model. The flow is simple to describe. Launch a browser, intercept requests, send the URL and a guiding prompt to an LLM, and return generated HTML or images to the page. In a recent post, he pushed the idea further with a proof of concept called Interceptium. It behaves like a request router inside the browser. Each request can be handled locally or passed through, the request can be modified, the network response can be captured, and then an LLM can render a tailored HTML view before the browser shows anything. You can read his write up here: aifoc.us.
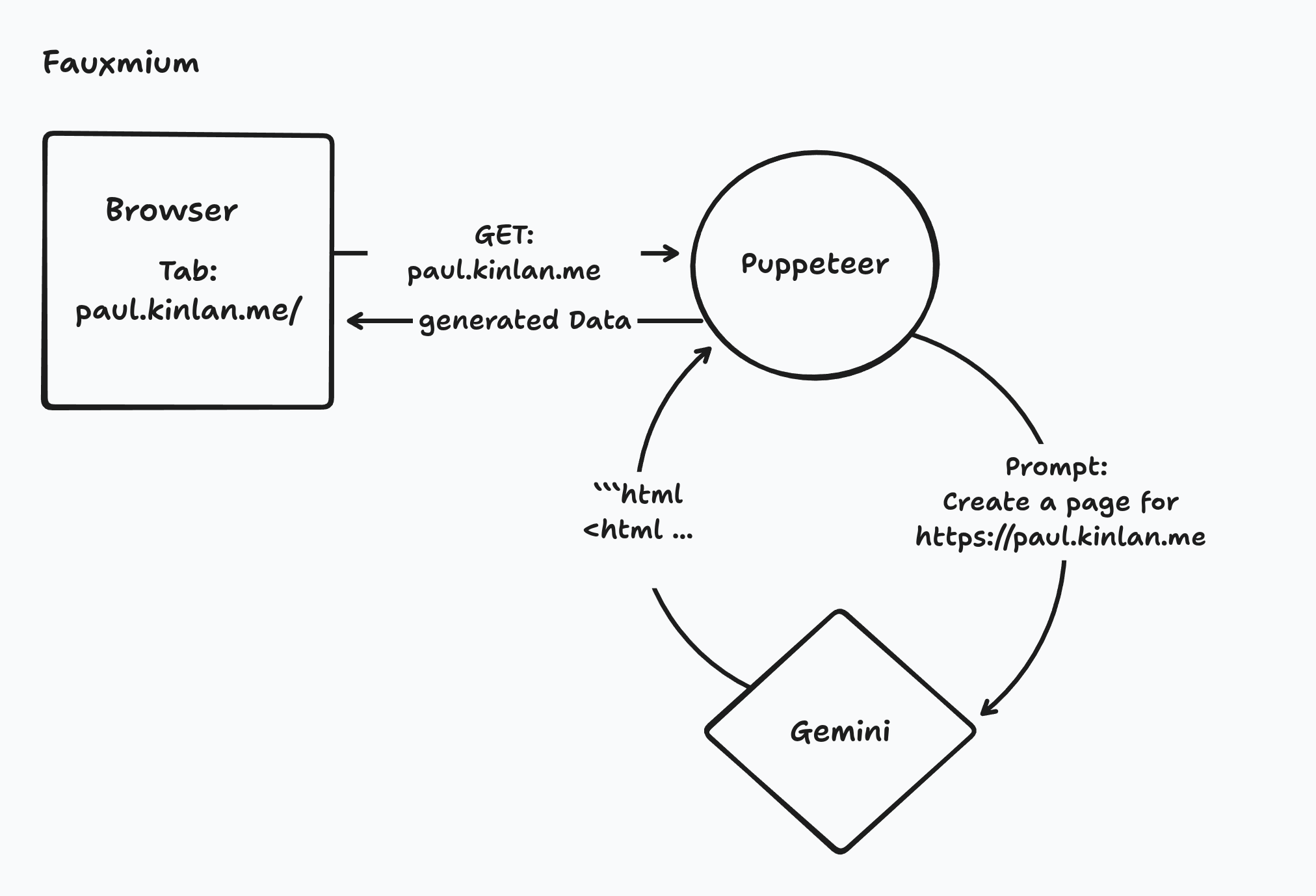
Why is this interesting. It lets you build interceptors that craft pages to your needs without the site author changing a line of code. One interceptor might summarize home pages. Another could translate content into your preferred language. A utility could find unstructured specs in a paragraph and turn them into a clean sortable table. You could insert a floating table of contents, highlight the details you care about such as kid friendly hotels or fast Wi Fi, or remap a recipe with instant serving sliders and metric conversions. There are real risks. Powerful interception creates security concerns, invites prompt injection, and can add heavy performance and energy costs. Even so, the approach hints at a browser future where the request lifecycle is programmable end to end.
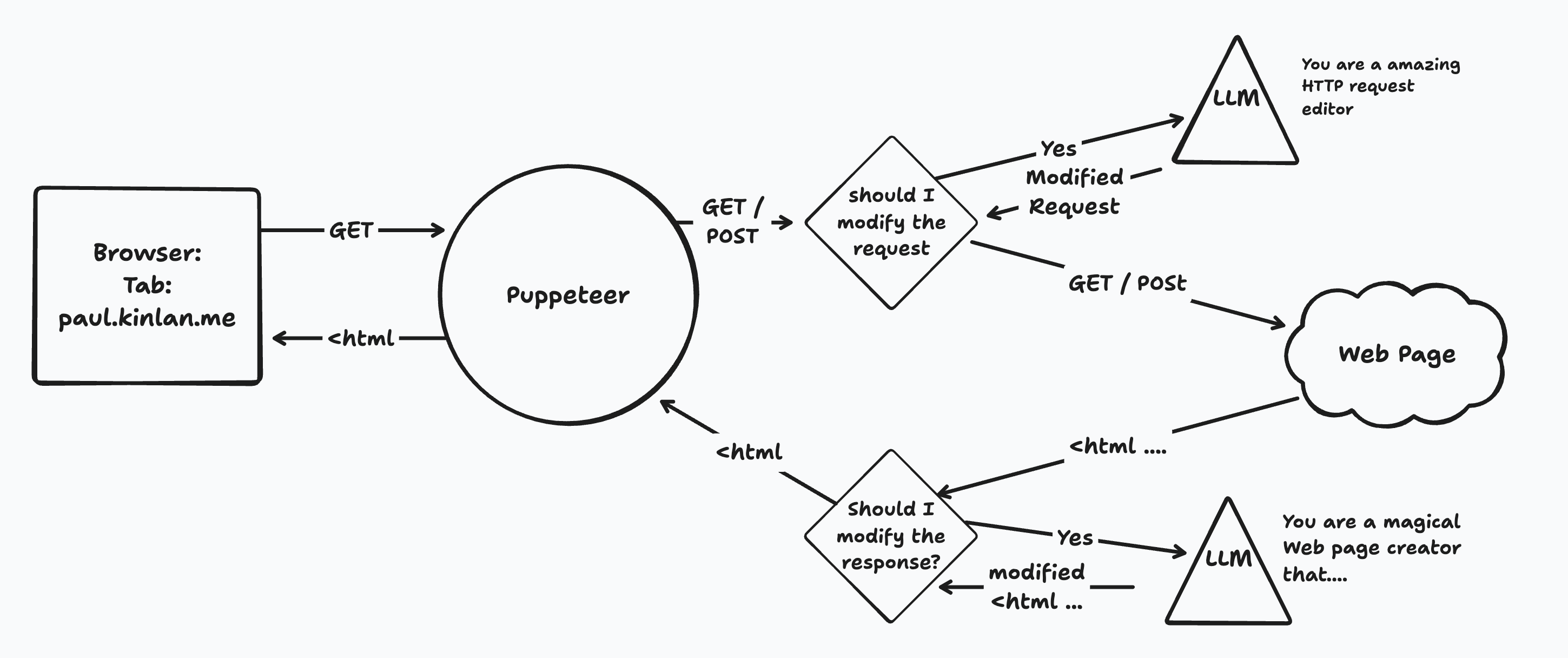
Here is the big unlock for dynamic UI. Personalization moves from the app to the browser. The page you load becomes a starting point that the client can reshape in real time based on your context, history, and intent. Shopping flows could collapse comparison work into a single view that merges specs, reviews, and past preferences. Research could turn every article or PDF into a summarized, citation rich card with automatic links into your notes. Accessibility can improve as interceptors restructure headings, add landmarks, and generate media alternatives on the fly. Interfaces stop being one size fits all and become adaptive compositions that the client assembles per user, per task, per moment. If browsers embrace safe interception APIs, this could be the biggest change in how we experience the web since client side scripting made pages interactive.
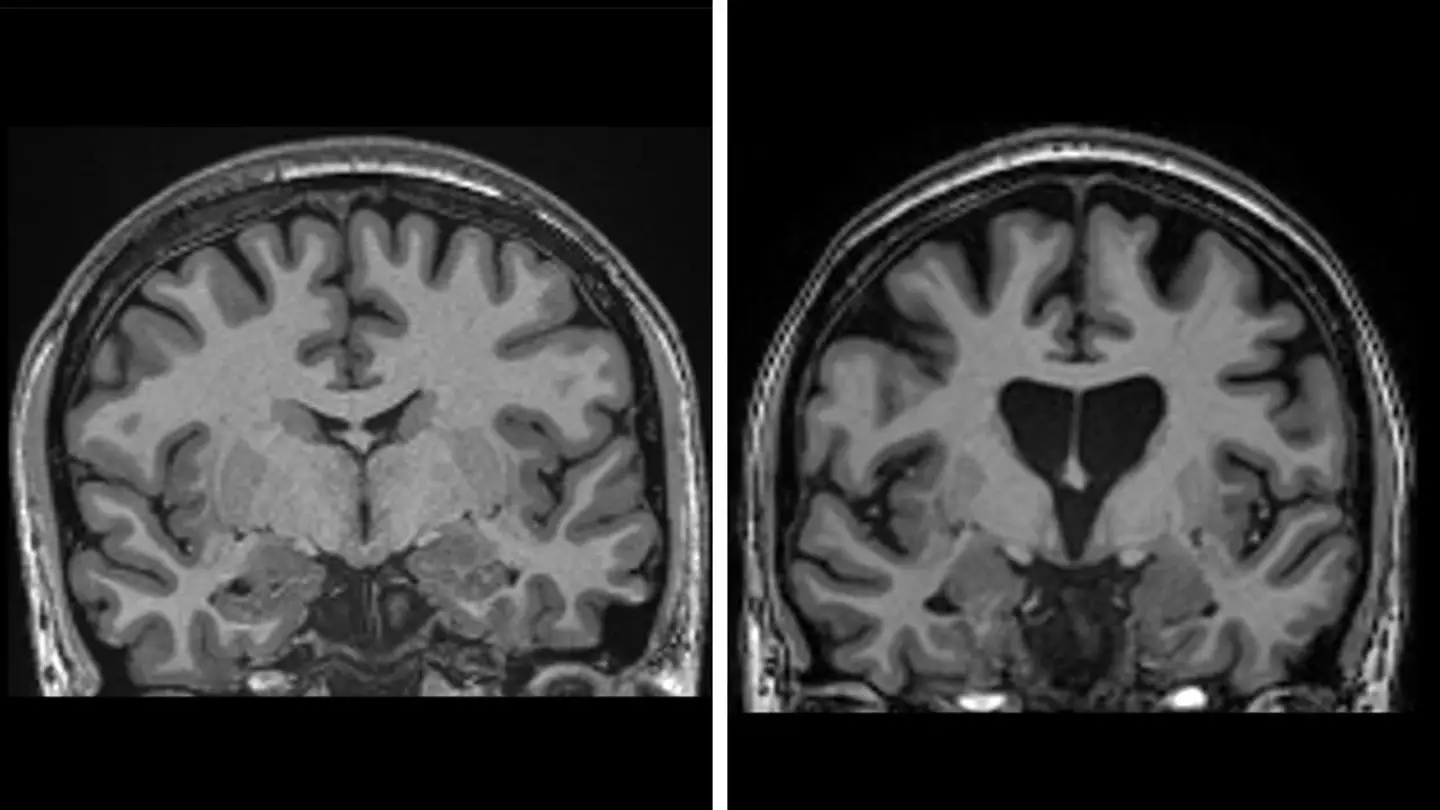
Doctors have achieved the first successful treatment of Huntington’s disease, a devastating genetic disorder that progressively destroys brain cells and mirrors symptoms of dementia, Parkinson’s, and motor neuron disease. The breakthrough involved a form of gene therapy delivered through 12 to 19 hours of intricate brain surgery. While the procedure is expected to be costly, it has proven safe. Data shows that three years post-surgery, the therapy slowed disease progression by an average of 75%.
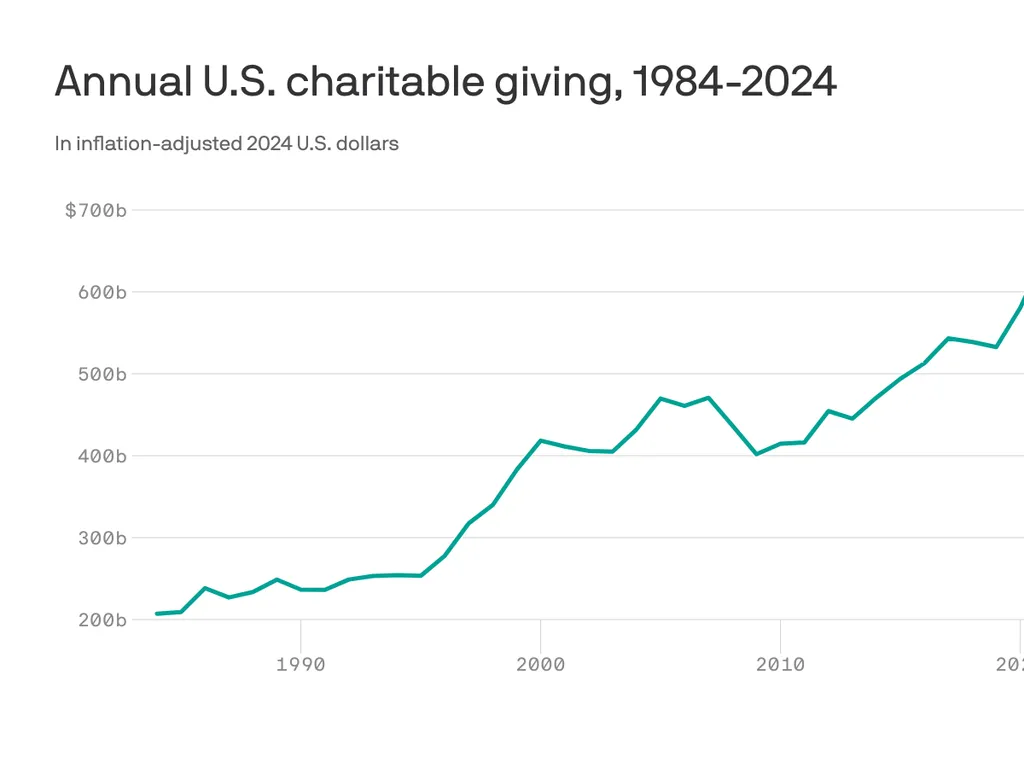
Charitable giving in the U.S. climbed 3.3% in 2024 after adjusting for inflation, reaching $592.5 billion. Individuals accounted for about two-thirds of the total, while corporate donations rose 6%. Growth was especially strong in public-society benefit organizations, fueled by contributions through donor-advised funds.
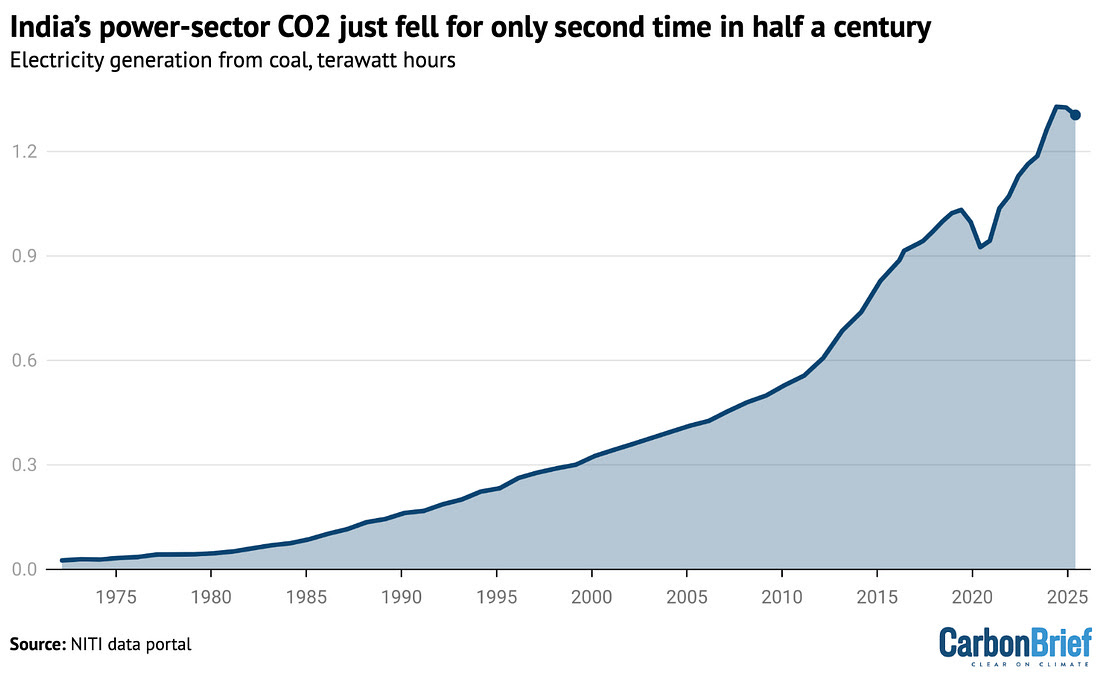
India’s power sector recorded its second decline in emissions in 50 years during the first half of 2025. With 234 GW of renewable capacity under construction or secured, analysts believe the sector could reach peak emissions before 2030. Such a turning point would represent a major shift in the energy path of the world’s third-largest emitter.
The U.S. Interior Department has approved $54 million to preserve 21,737 acres of waterfowl habitat and expand four national wildlife refuges in Utah, Tennessee, and Louisiana. The funding comes from the long-standing sale of federal “Duck Stamps,” a cornerstone of American conservation since 1934. Over the decades, these stamps have generated $1.3 billion, safeguarding more than six million acres of wetlands.

For the first time in nearly a century, swimmers returned to the Chicago River. About 300 participants completed a loop through downtown in the first sanctioned swim since 1927. The event was made possible by decades of cleanup efforts, beginning with the establishment of the EPA and the Clean Water Act in the 1970s. Volunteers and new infrastructure have restored the river’s ecosystem, drawing back fish, beavers, and even “Chonkosaurus,” a massive snapping turtle.

Enjoying The Hillsberg Report? Share it with friends who might find it valuable!
Haven't signed up for the weekly notification?
Subscribe Now