Quote of the week
“It’s not what you look at that matters, it’s what you see.”
- Henry David Thoreau

Edition 34 - August 24, 2025
“It’s not what you look at that matters, it’s what you see.”
- Henry David Thoreau
A new MIT study from the NANDA initiative reports that about 95% of company generative AI pilots are failing to create measurable business value. The report highlights a divide between organizations that try to build everything internally and those that buy focused tools from vendors. The latter group fares much better. The study also notes that the best early returns are showing up in back office automation rather than front line sales and marketing. Read the Fortune writeup.

Why so many failures? First, employee resistance slows adoption. Teams are unsure what will change, lack training, or simply do not trust the outputs. Second, the quality bar is uneven. Models hallucinate, lack grounding in company data, and are rolled out without clear accuracy thresholds or feedback loops. Third, resources are misallocated. Budgets chase splashy demos and front office use cases while neglecting integration, data cleanup, and the quiet back office work where ROI is stronger. Successful programs pick one painful workflow, wire AI into the process, and measure outcomes.

It helps to name the two software modes at play. Deterministic software produces the same output for the same input. It is predictable, testable, and required anywhere correctness is non-negotiable. Probabilistic software is where the same input can yield different outputs. It is powerful for drafting, summarizing, classifying, or ideation, but it is not guaranteed to be correct every time. As discussed on this week’s All-In Podcast, Chamath Palihapitiya frames this difference clearly around the 11 minute mark. Watch the episode.
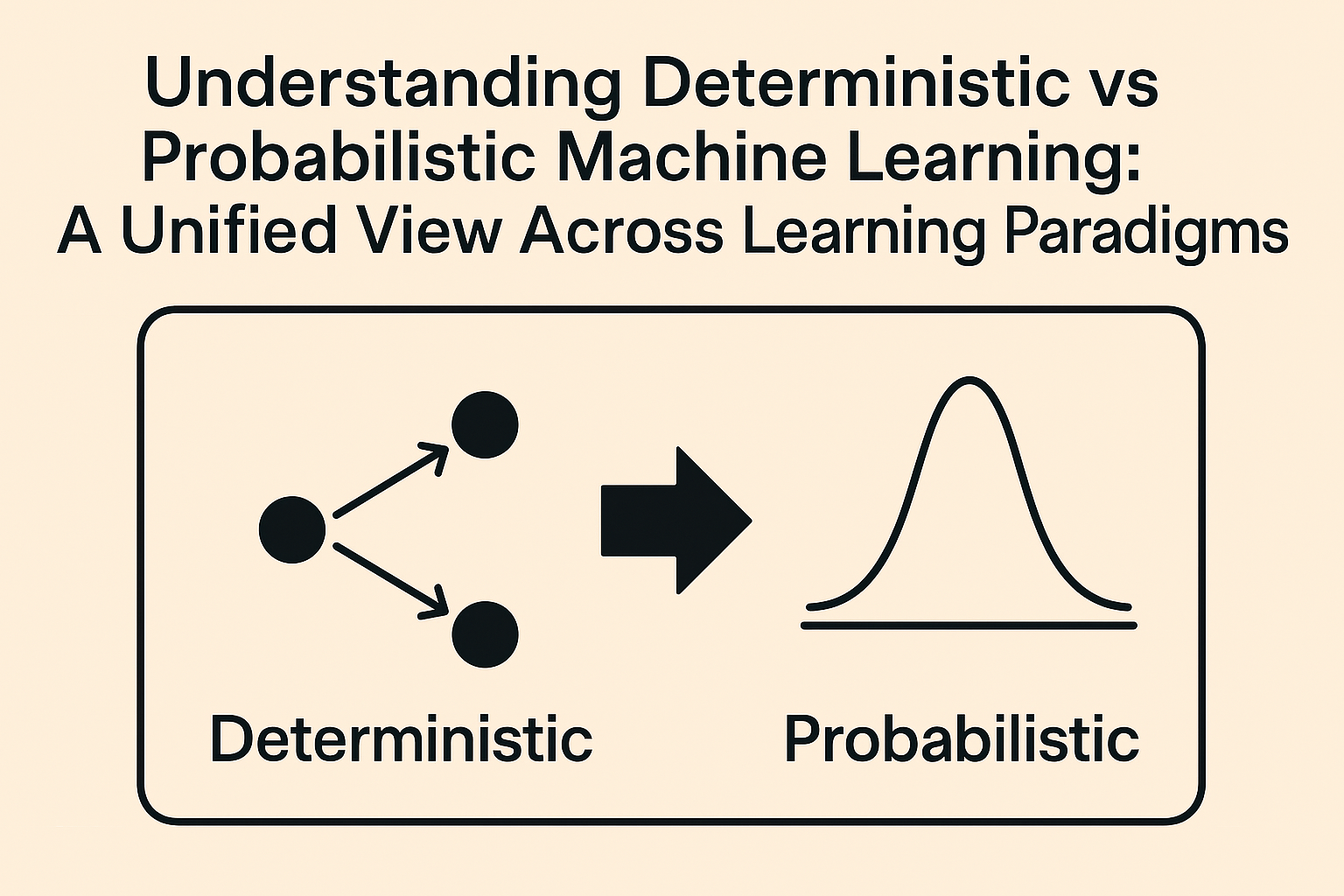
My take: both modes belong in the same application. Many industry processes must remain deterministic because even rare mistakes are unacceptable. Keep those steps strict and auditable. Then add probabilistic helpers around them. Look for the spell-check moments in your workflows where suggestions, summaries, and highlights can speed people up without taking control away. Leaders should either learn how the AI stack works or bring their in-house experts into every strategic decision about where to invest. It is fine not to know everything. It is not fine to pretend you do and make business-critical decisions because of that.
A chart that will keep popping up until there is true ASI is the Gartner Hype Cycle. It was introduced by the research firm Gartner in 1995 as a way to describe the maturity and adoption of emerging technologies. Gartner analysts developed it to help executives and investors understand how public perception often moves faster than real capability. The cycle has since become one of the most recognized tools for explaining why technologies are often overhyped in their early days and underestimated later, just before they reach practical, productive use.
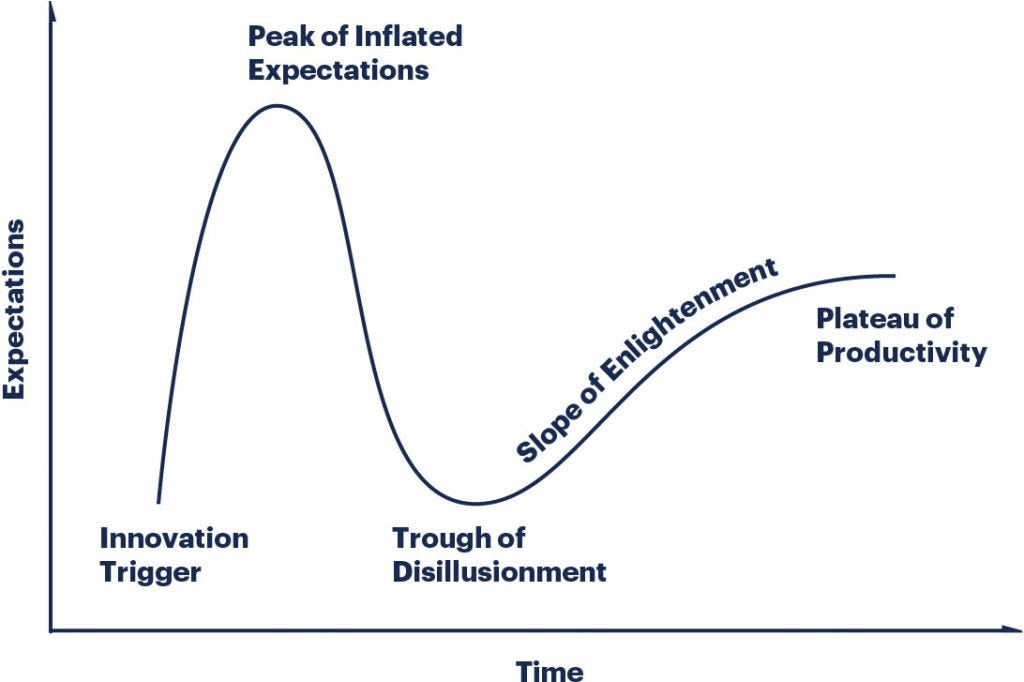
In my view, the innovation trigger for this era was the ChatGPT launch. The peak of inflated expectations was GPT-4, the last big leap from OpenAI, which remains the most widely used model provider. Today we sit in the trough of disillusionment. Some argue innovation has slowed. Others believe AGI or ASI is right around the corner. Businesses are revising their AI strategies, investors are calculating returns on invested capital for existing GenAI tools, and opinions on the future are scattered. No one can agree on where we go next.

My prediction is that investment will remain strong for years. Large language models will continue to improve, but in more linear steps rather than exponential jumps. Look at this OpenAI timeline, which shows how different GPT versions responded to the same prompt. The gains are clear, but the leaps are smaller with each release. Most people still don’t understand the limitations of LLMs, which sets expectations unrealistically high.

It is also worth remembering that LLMs are just one branch of AI. They share core building blocks like neural networks and transformers with other models, but their design constrains them to text prediction. That makes them great at generating words, explanations, and summaries, but they cannot think original thoughts or reason like humans. True intelligence (or ASI) will require technologies we have not discovered yet. Until then, every AI system will reflect the boundaries of its design, no matter how convincing its outputs may appear.

Not everyone loves video games. If that is you, feel free to skip this one and move on. For the rest of us, come along for a short rant.
We have all felt it. You are cruising in a match, then you get deleted in what feels like a millisecond by someone across the map. Rage spikes. I yell out loud - my wife can confirm it. You file an in-app report, then blame the devs for not stopping cheaters.

Here is the reality. Catching cheaters is harder than it looks, but targeted statistical analysis can help a lot, especially in a first person shooter like Apex Legends (my current favorite game). Pure stats alone will not catch everything. Wall hacking often needs different signals, and aim bots now try to look human by adding randomness or toggling on and off. Still, accuracy based detection is a strong pillar if you do it right. Build baselines by platform and input device, then segment by weapon, distance, target movement, player movement, field of view, and ping. Compare each player’s per-life and per-match patterns to high skill human distributions. Watch not only raw accuracy but also time to kill versus theoretical limits, headshot rate versus distance, reaction time from first visibility to first hit, recoil control patterns, and the angle and speed of aim adjustments. Outliers happen, so use sequential tests and confidence intervals, not single hard thresholds. When signals stack across matches, confidence rises.

Start with the metrics that matter. Use pro and top ranked players to set your human reference, but also build a matched cohort baseline for each player’s device and region. Each time a player is reported, pull the last several games. Run accuracy and timing models against the standards above. If the profile is statistically incompatible with human play after accounting for aim assist, network conditions, and weapon mix, take action. High confidence should trigger an immediate ban. Medium confidence should place the account in stricter review, lower trust lobbies, or a shadow pool while you gather more data. Low confidence should inform coaching prompts or be ignored. Add more layers: server side validation of line of sight before hits register, integrity checks to detect client tampering, honeypot entities that only wall hacks can see, and human review for edge cases.

On top of that, modern anti-cheat is moving deeper into hardware and firmware security. Online multiplayer games are increasingly requiring Secure Boot and TPM (Trusted Platform Module) to close the gap. As Andrew Moore explains, Secure Boot ensures the operating system has not been tampered with at startup, while TPM provides both a unique hardware identifier and proof of a clean boot state. These features prevent cheaters from injecting unauthorized kernel-level drivers and make hardware bans harder to evade since every machine can be uniquely identified. Combined with statistical analysis and behavioral models, these measures tighten the net around cheaters in ways that software alone cannot. A message to anyone who uses cheats in video games: You're a loser :p.
There has been a lot of chatter about the idea that “RAG is dead.” For instance, this Latent Space article explains why. Chroma’s founder argues RAG is dead because it bundles three concepts poorly. The real job is context engineering — deciding what belongs in the context window for each LLM generation. The best teams now use a two-stage approach: first, retrieval through vector search, text search, and metadata narrows 10,000 candidates down to 300; second, LLMs re-rank those to the final 20–30. This matters because “context rot” is real. Despite needle-in-haystack marketing, models degrade as more tokens are added. The future may look radically different, with models retrieving continuously in latent space instead of converting back to text. What we currently call “memory” is essentially context engineering under a better name.
In practice, many people misunderstand what RAG can and cannot do. They think of it like fine-tuning or reinforcement learning — apply it and your use case will automatically improve. That is not how it works. RAG is not dead, but it is not a magic upgrade either. It is a tool that works well in certain situations and poorly in others.

So where is RAG actually useful? Two real-world examples can help you think about it. First, compliance and policy lookup: when a company has thousands of pages of regulatory or internal policy documents, RAG helps by retrieving the most relevant snippets into context, so employees can ask plain-language questions and get grounded answers. Second, customer support knowledge bases: when users submit tickets or questions, RAG can retrieve exact product documentation, FAQs, or troubleshooting steps so the model provides accurate responses rather than making things up. In both cases, the value comes from narrowing down large unstructured corpora into focused, model-readable context — not from trying to make the model “smarter.”
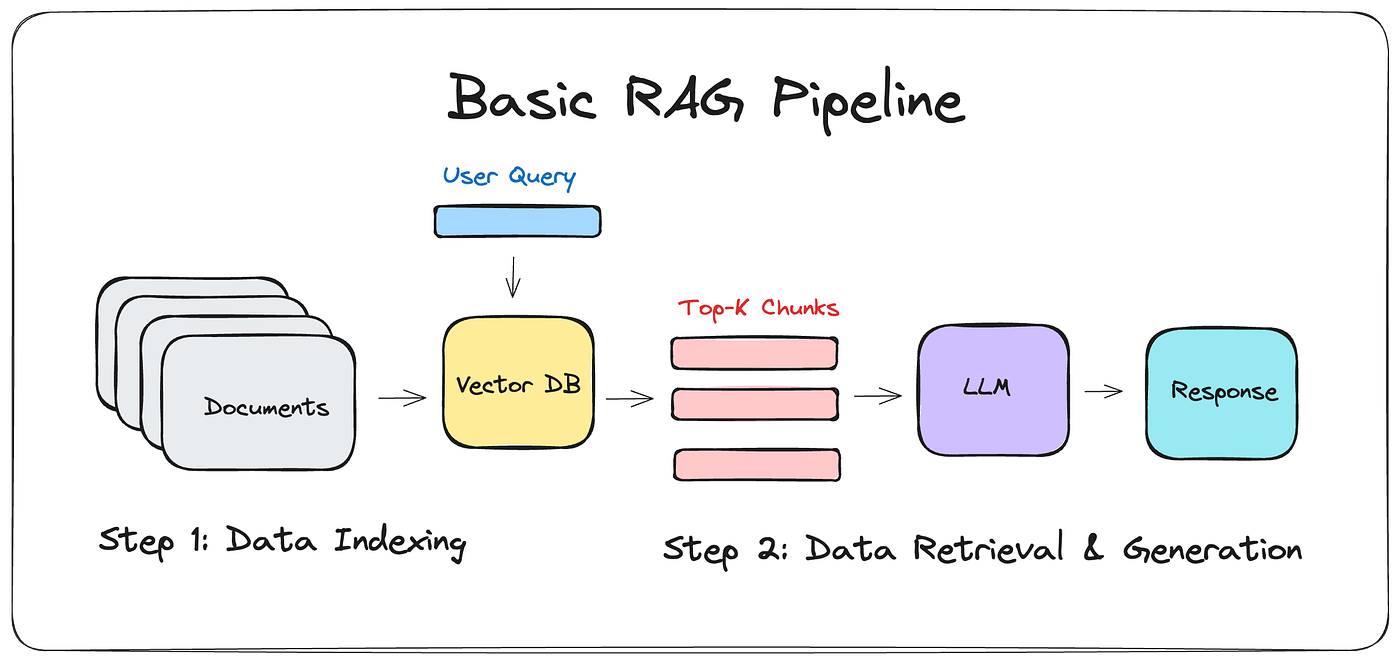
As you can see, RAG is far from useless. The key is knowing when and how to apply it. On the other hand, people need to understand the broader landscape of AI technologies before making resource decisions. Too often, leaders don’t know the differences between fine-tuning, RAG, prompt engineering, or reinforcement learning, and so funds get misallocated. This is exactly the kind of misdirection and waste the MIT study highlighted in the first article of this edition. Knowing when to use RAG, and when not to, can make the difference between failed pilots and real business value.
Mexico has lifted 13.4 million people out of poverty since 2018. During that time, the share of the population living in poverty dropped from 41.9% to 29.6% — the steepest reduction in the country’s history. President Claudia Sheinbaum praised the results this month, saying: “We have to be very proud as Mexicans because this indicator speaks of the essence of our project — humanism.”

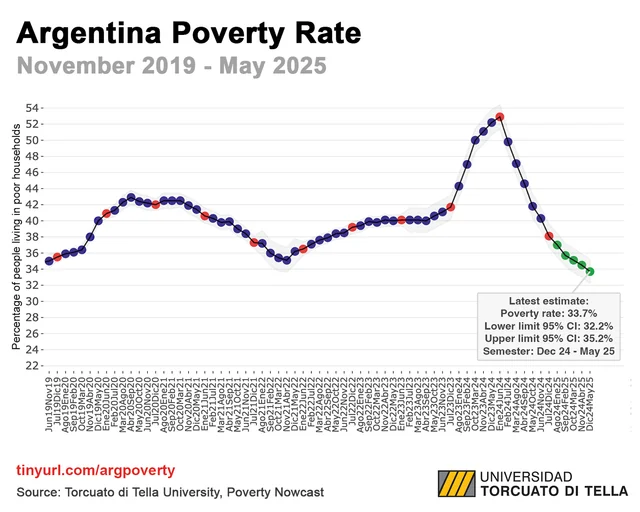
After stabilizing runaway inflation, Argentina has seen extreme poverty fall sharply. In the first half of 2025, the rate dropped to 7.4%, down from 18.2% just a year earlier. The turnaround stems from inflation cooling: monthly rates have stayed below 2% for two months in a row, compared with more than 200% at the end of 2023.
Across Europe, fewer children are being left behind. Severe material and social deprivation among children in the EU fell from 11.8% in 2015 to 7.9% in 2024, with Romania and Hungary showing the greatest progress. Nutrition is improving as well: daily fruit and vegetable consumption among low-income children rose from 87.2% in 2014 to 91.7% in 2021. Much of this change comes from the European Child Guarantee, which directs funding toward childcare, housing, food, and healthcare.

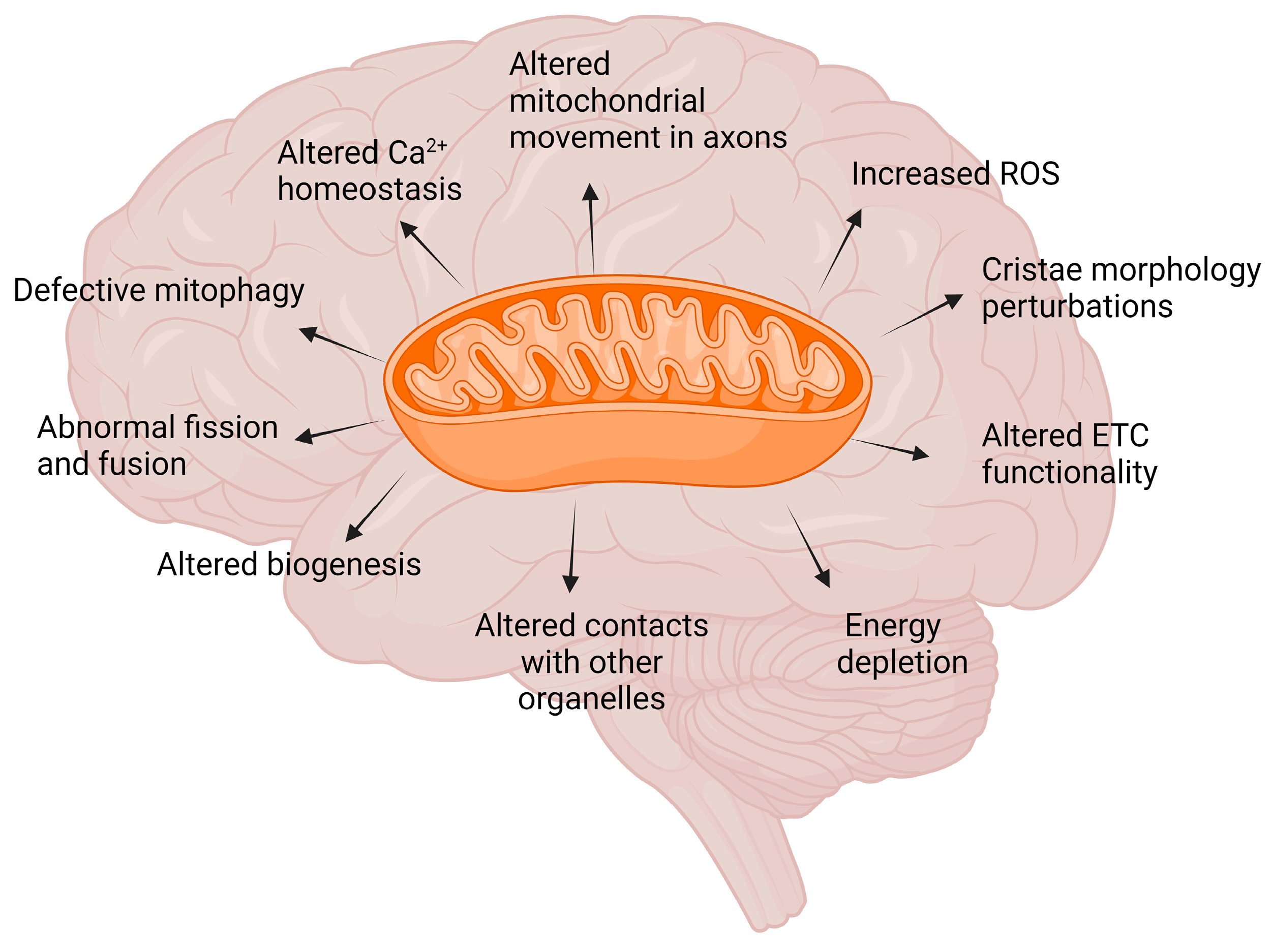
Scientists can now restore memory by recharging the brain’s energy systems. French and Canadian researchers discovered that faulty mitochondria — the cell’s “powerhouse” — directly drive memory loss in dementia. By boosting mitochondrial activity in mice, they were able to restore memory, proving the link for the first time. The findings suggest mitochondria could be a major target for future therapies to slow or prevent neurodegenerative diseases like Alzheimer’s.
Oil tanker spills, once routine disasters, have nearly disappeared since the 1970s. Back then, spills released an average of 314,000 tonnes of oil into the ocean every year. Today, that figure is below 10,000 — less than one-thirtieth of its former level — thanks to improved ship design, tighter regulations, and faster response systems.

Cotton farmers are adopting natural pest control methods. Entomologist Robert Mensah developed a simple mixture of yeast, sugar, and water that attracts ladybirds and lacewings, insects that prey on crop pests. The technique has spread from Australia to Benin, Ethiopia, Vietnam, and India, reducing pesticide use while protecting farmers’ health.

Enjoying The Hillsberg Report? Share it with friends who might find it valuable!
Haven't signed up for the weekly notification?
Subscribe Now