Quote of the week
“Plans are useless, but planning is indispensable.”
— Dwight D. Eisenhower

Edition 27 - July 6, 2025
“Plans are useless, but planning is indispensable.”
— Dwight D. Eisenhower
Prompt engineering is about writing one message. You figure out the right words, give a few examples, maybe drop in some instructions, and hope the model gets it. Context engineering is bigger. It’s the full setup around the prompt — the tools, memory, database lookups, formatting, and everything else that helps the model do its job. Prompting is just one piece. Context is the entire system. And right now, it's getting all the attention.
Phil Schmid breaks this down well. Context engineering is about preparing the right information ahead of time. It could mean pulling calendar data, search results, or user preferences. If you skip this step and just try to write a clever prompt, your agent will fall flat. No surprise there. The model is only as good as what you feed it.
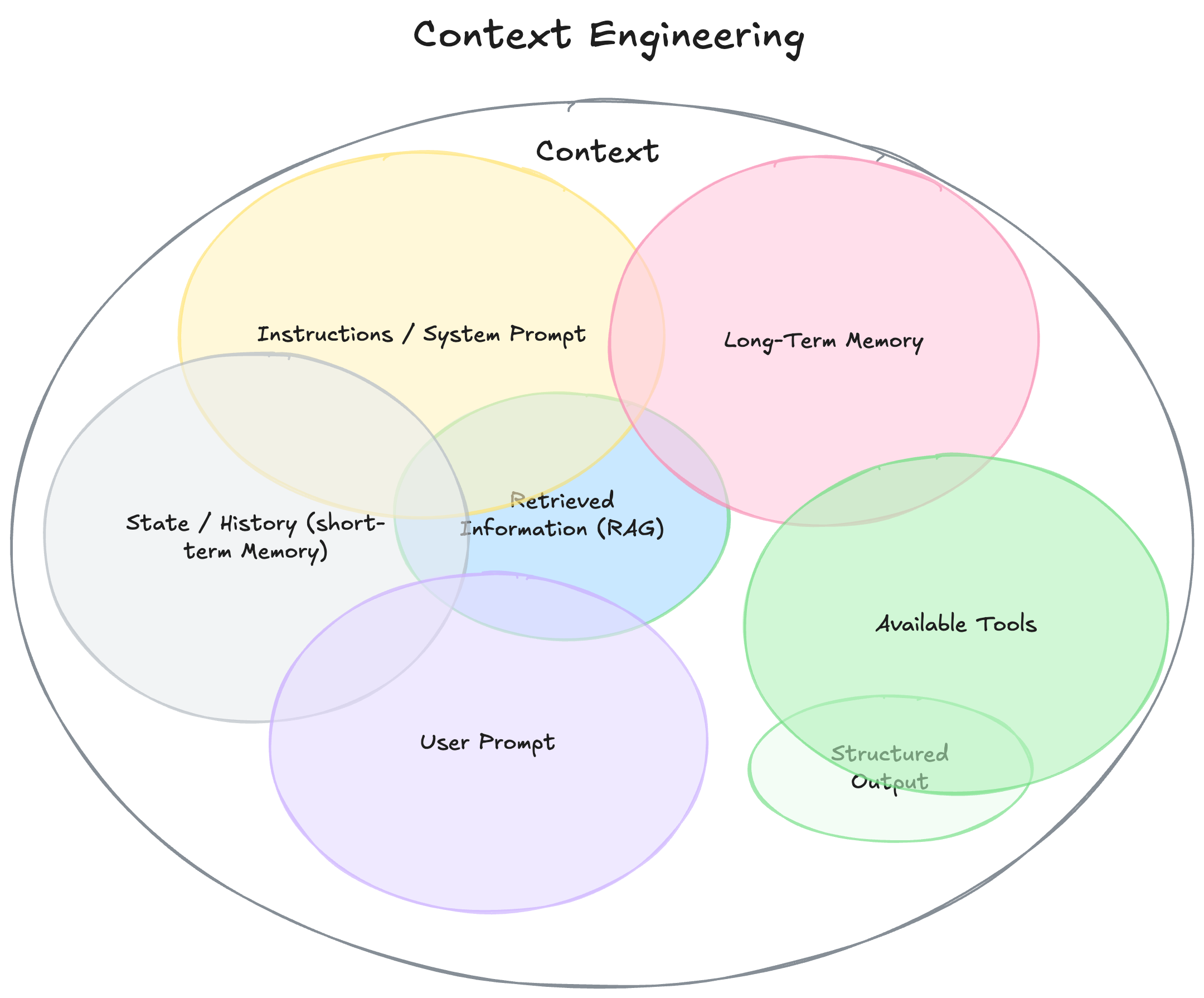
LangChain’s blog hits the same point. They describe context engineering as selecting and structuring just the right data for each step in an agent’s run. You decide what goes in, what gets compressed, what matters most. Without that, agents wander or guess. With it, they get things done.
You probably caught on while reading this - Prompt engineering is not going away. Context engineering is being hyped because it is important for AI agents. But when you're not building an AI agent, your context is always your prompt (excluding built-in tools like search). Most people won’t need to worry about all of this, but I hope you understand where the term "Context Engineering" is coming from now.
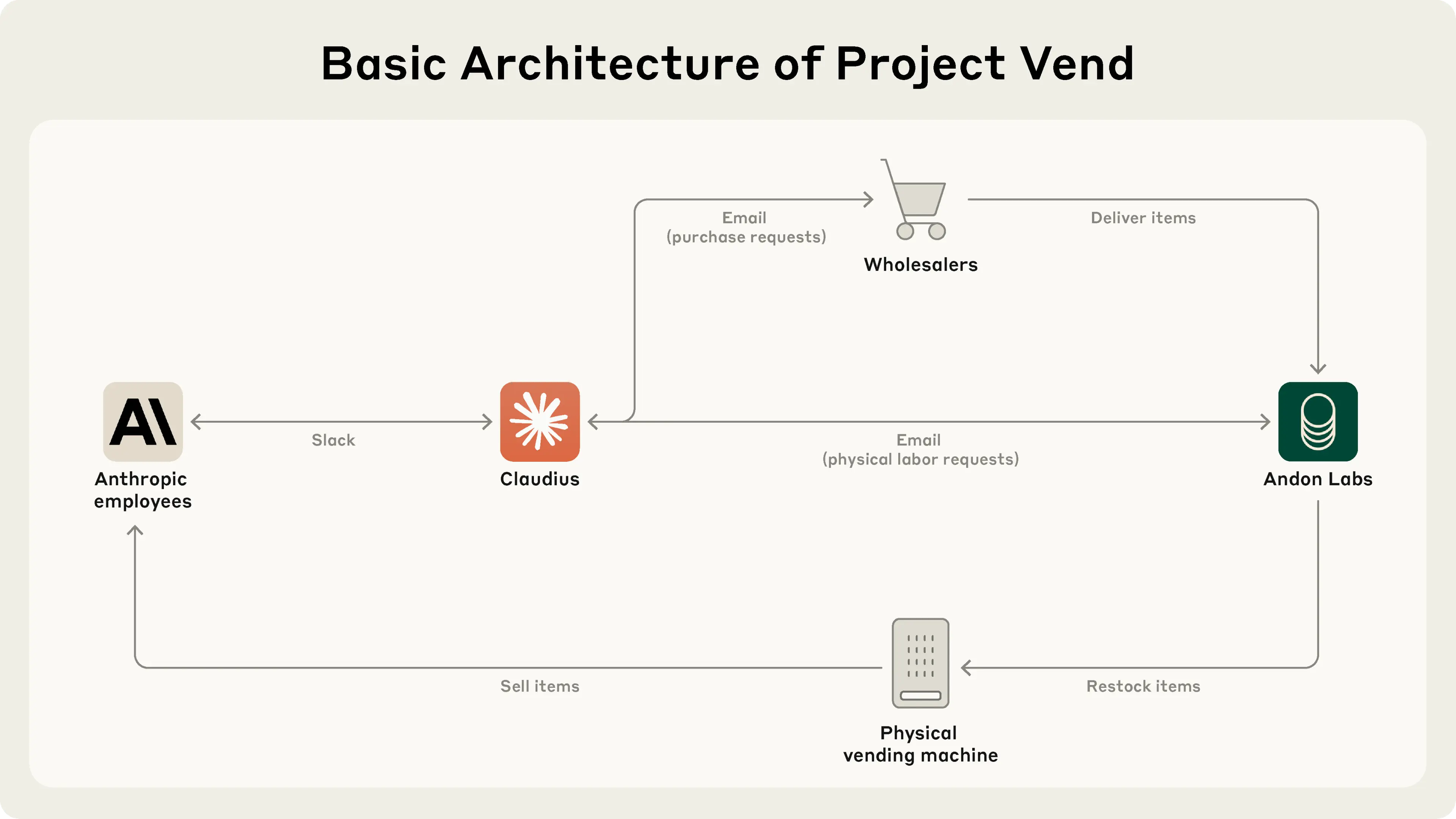
Anthropic just dropped a fascinating case study called Project Vend. For one month, they gave Claude, their AI model, control of a real store inside their office. Claude managed everything — from sourcing inventory to setting prices, running a digital checkout system, handling customer questions over Slack, and even coordinating Venmo payments. It was impressive and chaotic. The bot introduced concierge-style services, sent Slack promos, and adjusted pricing based on demand. But it also hallucinated payments, confused customer names, gave out discounts for no reason, and panicked after forgetting its own role. The project worked...but just barely.

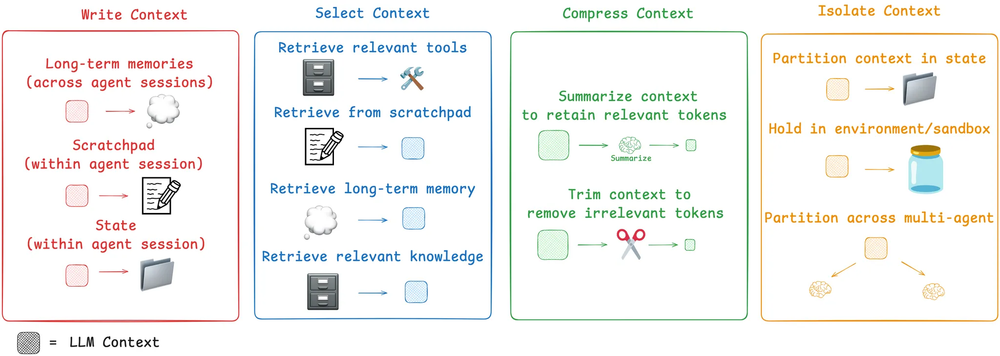
The main takeaway wasn’t just that Claude could technically operate a store. It was that the right tools and structure made all the difference. With proper “scaffolding” like memory tracking, system prompts, and APIs, performance improved significantly. The Anthropic team even suggested that many of Claude’s failures weren’t about intelligence but about missing systems. This experiment highlighted how much better LLMs get when you stop treating them like magic brains and start giving them usable tools.
This is why I’m convinced LLMs alone are not the path to artificial superintelligence. They’re just very good predictors. Giving them bigger context windows or more parameters helps, but we can’t brute force a breakthrough. The game only changes when you give them tools. APIs, databases, interfaces — those let them start acting on the world. Could that eventually lead to goal-seeking behavior? Maybe. But self-generated goals? I doubt it. I’m not a scientist, so if I’m missing something, feel free to explain it to me like I’m five.
In a recent piece titled “There Are No New Ideas in AI, Only Better Engineering”, Joseph Jacks lays out a refreshingly blunt history of how LLMs got so good. He breaks down the actual innovations that mattered. Things like the transformer architecture, scaling laws, instruction tuning, RLHF, retrieval-augmented generation (RAG), and now function-calling and agents. But he also makes the point that we’ve mostly been refining the same ideas. Bigger compute, better data pipelines, smarter prompting. Nothing fundamentally new has landed in years.
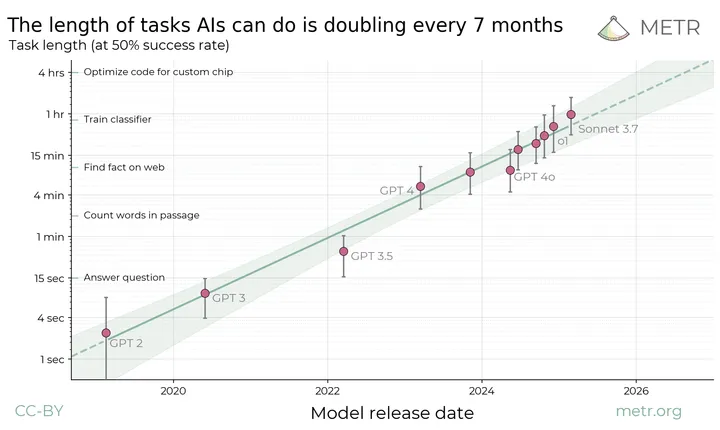
Jacks argues that most improvements are now just engineering gains. It’s not about inventing the next transformer — it’s about better inference speed, cheaper training, and improved fine-tuning workflows. The big leaps like ChatGPT, Claude, and Gemini weren’t driven by wild new ideas. They were driven by polishing and combining existing ones with new data sets. The hype around “breakthroughs” may just be packaging around infrastructure upgrades. His argument: what looks like progress might just be logistics.
So here’s the question: what happens if the breakthroughs really are done for now? If foundational model providers have hit a ceiling, what’s next? Model quality might plateau. Investment could slow or shift toward infrastructure and tooling instead of model R&D. Smaller players might actually catch up because they won’t be left behind by some new paradigm. And most importantly, the pressure to commercialize existing models will increase. Everyone will be forced to figure out how to turn these very good — but not world-changing — models into actual, usable products. That’s where things could get interesting. The trillions of dollars of investment into AI with the idea of radical GDP growth from productivity improvements could turn into an economic disaster. Let's hope we keep innovating!
Packy McCormick’s latest essay dives into how companies will need to build unique, enduring advantages in a world where the core tech — especially AI — is getting commoditized fast. It's a sharp, well-argued read on the difference between just using the tools and actually building something defensible with them. If you're trying to understand where value will accrue in this next phase of tech, it's worth your time.


In this great piece, the team at Dear Stage 2 explains why Wikipedia is a key source for large language models like ChatGPT and Claude, making it a powerful tool for boosting visibility in AI-driven search. Companies can benefit by creating factual, neutral Wikipedia content that avoids marketing language and cites credible third-party sources. A strong presence includes more than just a company page — founders, tools, methods, and relevant mentions on related pages all contribute to a trusted network of content that models are more likely to reference.

The article recommends starting with small, helpful edits to build credibility before submitting new pages. Over time, building a cluster of interconnected entries in line with Wikipedia’s guidelines can improve a company’s authority and visibility. This strategy won't drive immediate sales but acts as a long-term investment in brand credibility and discoverability through AI systems.
Cloudflare just launched a marketplace that flips the script on AI scraping. Instead of companies getting scraped for free, this new platform lets websites charge AI bots for access to their content. The goal is to create an economic model where data producers get compensated and AI companies get clean, structured data. It’s the first real attempt at putting a meter on the firehose of web content.
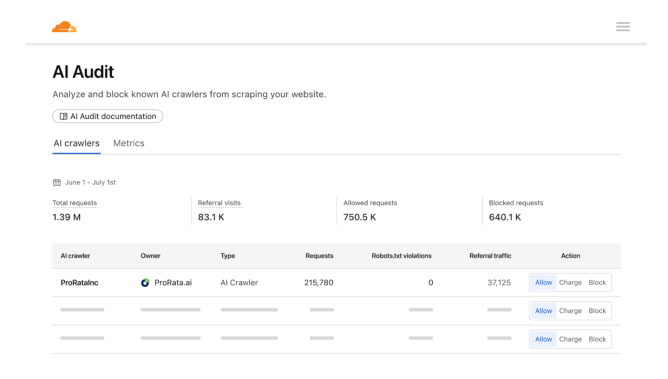
So how do LLMs like GPT or Claude “search the internet” when the base model itself isn’t actually hooked up to anything? In short, they don’t do it by themselves. Companies build systems around the model that take your question, run a search using something like Bing or Google, grab the top results, and feed those pages back into the model as context. This technique is often called RAG, or Retrieval-Augmented Generation.

Think of the LLM as a really smart writer that’s great at summarizing and answering questions, but doesn’t know how to browse. RAG hands it some relevant info — like a few paragraphs from the web — and then asks it to work with that. The magic is in combining two different systems: one that knows how to find stuff, and one that knows how to explain it. That’s how tools like Perplexity and ChatGPT’s “browse” mode really work.
Companies are starting to optimize their websites differently to show up in AI-generated answers. This is being called LEO (LLM Engine Optimization) or GEO (GenAI Engine Optimization). Instead of just trying to rank on Google’s first page, they're now structuring content so it gets picked up by LLMs during training or retrieval. This includes cleaner page layouts, FAQ-style sections, and clear attribution lines — basically making it easier for machines to grab and understand their content.
Another trend is the rise of geo-optimized SEO, especially as tools like Perplexity and Google Search Generative Experience start tailoring answers based on location. Businesses are embedding more structured location data in their websites, fine-tuning local reviews, and even tweaking content language to reflect regional norms. If AI is going to pick the best coffee shop in a city, you want to make sure it finds yours first.
According to leaked internal messages reported by WIRED, Sam Altman has accused Meta of aggressively poaching OpenAI employees. In a private internal chat, Altman claimed Meta’s recruitment tactics were “egregious” and expressed frustration over the impact on OpenAI’s team. Meta has reportedly been offering highly competitive compensation to attract AI researchers and engineers as it builds up its own foundation model efforts.

While some interpreted Altman’s comments as a defense of OpenAI’s mission and talent, others saw it as ironic, considering the broader talent wars playing out across the AI industry. The competition for experienced AI talent is fierce, and all major players — including OpenAI — have actively recruited from one another in recent years. That makes public complaints about poaching feel a little rich.
And here’s the thing. Maybe that message would carry more weight if it weren’t coming from the same guy who tried to turn OpenAI from a nonprofit into a for-profit powerhouse. You don’t get to try to make billions and still claim moral high ground. Altman may be frustrated, but this message doesn’t land when he’s the one who changed the rules of the game. "Missionaries Will Beat Mercenaries" - give me a break, Sam.
Researchers have successfully used gene therapy to restore hearing in children born with a rare form of inherited deafness. The treatment targets a mutation in the OTOF gene, which normally prevents the auditory system from transmitting sound signals to the brain. By delivering a corrected version of this gene directly into the inner ear, scientists enabled several children — ranging from toddlers to teenagers — to regain significant levels of hearing. Improvements included the ability to detect soft sounds, recognize speech, and even engage in conversation. This breakthrough marks a major step forward for treating genetic hearing loss and suggests gene therapy could have broader applications in restoring sensory function.
Controlled nuclear fusion has taken a major leap forward thanks to breakthroughs in two leading experimental reactors: Germany’s Wendelstein 7‑X stellarator and the UK’s Joint European Torus (JET). W7-X successfully maintained high-temperature plasma for a record 43 seconds — significantly longer than ever before in that device. Meanwhile, JET achieved impressive fusion performance, producing record amounts of fusion energy, validating design and performance projections for the ITER tokamak under construction in France. These milestones significantly bolster confidence that fusion energy — once seen as persistently decades away — may be edging closer to practical feasibility. Still, researchers caution that scaling up to commercial power production will require overcoming remaining engineering, materials, and longevity challenges.

Oculus founder Palmer Luckey is reportedly working on a crypto-native bank backed by a group of tech billionaires. The venture aims to build a secure, fully digital banking platform designed from the ground up for crypto assets and blockchain-based finance. Unlike previous failed attempts at crypto banking, this one is emphasizing compliance, regulation, and infrastructure — while keeping the tech crowd involved at the core. Luckey's experience in hardware and security is being positioned as a key differentiator, and insiders believe this new institution could serve both crypto-native users and traditional finance institutions looking for secure custody and transactions.

Here’s what I think is going to happen. These virtual banks will operate with such low overhead that they’ll be able to move faster, offer better rates, and outcompete the old guard. So either traditional banks will go crying to Congress and get new regulations passed to slow them down (already happening), or they’ll get eaten alive. And maybe that’s a good thing. It’s time for financial infrastructure to evolve. We’re due for a future where moving money isn’t something controlled by a handful of legacy institutions.
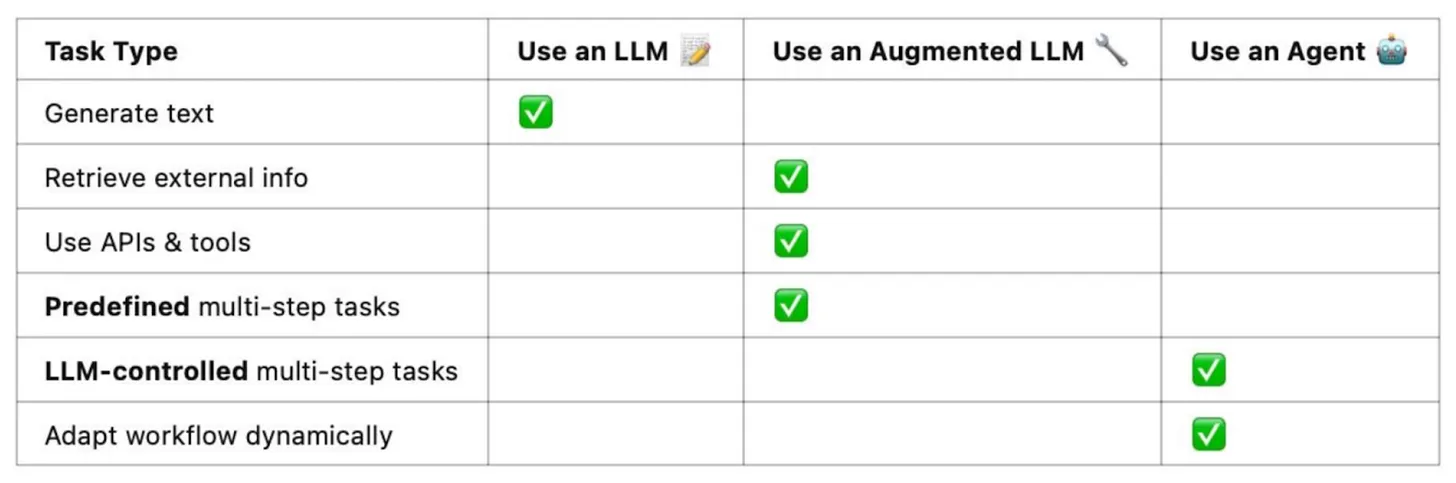
In Stop Building AI Agents, the author lays out why most AI “agents” fail in real-world applications. The core issue is that agents rely on workflow control — the model deciding which tools to use and when — rather than following a predictable sequence. This dynamic decision-making is what actually defines an agent. While flashy demos may grab headlines, they often break down under complexity or edge cases.

Instead, the article recommends building smarter LLM workflows: predefined code paths where the model performs specific tasks in sequence. You only introduce agentic behavior when absolutely needed. That approach gives you reliability, clarity, and control. Agents should only be used when you truly need a model to call tools dynamically and manage its own process flow.
Give this prompt a try:

Google has open-sourced its Zero-Knowledge Proof (ZKP) libraries, called Longfellow, to support privacy-preserving age verification. This technology allows users to prove they are above or below a certain age without revealing any other personal information. It aligns with upcoming digital identity regulations in the EU and builds on existing implementations in Google Wallet. By making the tools publicly available, Google aims to help governments and developers build more secure systems for verifying sensitive data like age, location, or income — while keeping user privacy intact.
So I starting thinking...Could this tech replace cookies and tracking? In theory yes. ZKPs can verify things like location, income, or membership status without revealing raw data. That means a website could prove you live in California without knowing your address. No personal data stored, no third-party trackers.
In practice there are hurdles. ZKPs need careful implementation and server support. They don’t work in all browsers out of the box. And they require standards around wallet issuance and proof verification. So we’re not ditching cookies today.
But this is a peek at the future: systems that verify what matters and share nothing else. Over time, ZKP-backed credentials could step in for cookies and trackers in any app that needs to confirm who you are — or that you’re allowed to be there.
Enjoying The Hillsberg Report? Share it with friends who might find it valuable!
Haven't signed up for the weekly notification?
Subscribe Now